- 개인용 컴퓨터에서 이용 가능한 의료 AI로 신사업 확장과 기술적 혁신 선도

고려대학교 컴퓨터학과 강재우 교수(사진) 연구팀, 아이젠사이언스, 임페리얼 칼리지 런던 대학(I,C,L)이 공동으로 개발한 sLLM(small LLM, 소형언어모델)인 Meerkat-7B가 70억개 매개변수 이하 소형언어모델로는 처음으로 미국 의사 면허 시험(USMLE)을 통과하는데 성공했다.
※ 연구 논문 URL: https://arxiv.org/abs/2404.00376
OpenAI, 구글 등 빅테크 회사들이 주도하는 LLM(거대언어모델)들이 성과를 보이고 있지만, 이는 외부 클라우드를 사용하기 때문에 병원이나 기업 등에서 사용하기에는 민감한 데이터가 유출될 위험이 있다. 이에 기관 내부에 설치해 보안성을 높일 수 있는 ‘온프레미스(On-premise)’ 방식이 가능한 sLLM에 대한 수요가 증가하고 있다.
sLLM은 모델의 매개변수(parameter)를 줄여 비용을 줄이고 미세조정(fine-tuning)으로 정확도를 높인 모델을 의미한다. 매개변수의 경우 OpenAI의 GPT-3.5(ChatGPT)는 1750억 개, 그리고 구글의 ‘PaLM’은 5400억개에 달하지만, Meerkat-7B는 70억개에 불과하다. 이는 PC 한 대에서도 설치 및 활용할 수 있는 크기의 모델이라는 점에서 의의가 있다.
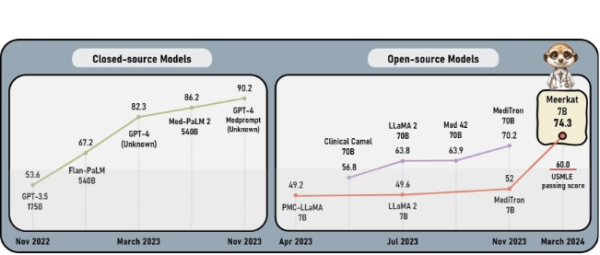
Meerkat-7B는 복잡한 의료 문제를 해결하는 데 필요한 다단계 추론 능력을 갖춘 의생명 분야에 특화된 sLLM 모델이다. 60점이 평균 합격선인 미국 의사 면허 시험에서 기존 최고 sLLM인 MediTron-7B는 52점으로 통과에 실패했으나, Meerkat-7B는 74점이라는 높은 점수로 통과해 그 성능을 입증했다. 또한 7개의 의료 벤치마크 성능평가에서 GPT-3.5(175B) 모델보다 평균 13% 높은 성능을 보임으로써, 의료 분야에서의 오픈 소스 모델 개발이 중요한 진전을 이루었음을 보여줬다.
Meerkat-7B와 같은 의생명 특화 언어모델은 병원 내에서는 임상 의사 결정 지원, 비표준화된 의료 차트의 정리와 같은 의료·원무 행정의 효율성을 제고하고, 제약 회사에서는 특허 분석, 임상 설계, 문서 작성 등의 노동 집약적이고 전문성을 요하는 업무를 지원해 각 분야 전문가의 업무 부담을 경감하는 데 기여할 수 있다.
강재우 고려대 컴퓨터학과 교수는 “의생명 분야에서는 매일 3000편 이상의 연구 논문이 발표되는데, 이렇게 방대한 정보 속에서 신약 개발에 필요한 새로운 질병 표적 단백질을 식별하고 검증하는 작업은 매우 시간이 소모되는 일이다.”라며 “Meerkat-7B를 통해 새로운 약물 타겟을 발굴하는 과정의 효율성을 대폭 향상시킬 수 있을 것으로 기대하고 이번 성과를 바탕으로 의료 특화 LLM을 활용한 신규 사업모델 또한 준비 중이다.”라고 밝혔다.
한편, 강재우 고려대 컴퓨터학과 교수는 인공지능(AI) 기반 신약 개발 회사인 아이젠사이언스를 창업하여 암 및 희귀·난치성 질환 치료제 등 14개의 자체 약물 개발 프로젝트를 진행하고 있다. 아이젠사이언스는 제약 및 의료 산업 전반에서 AI를 통한 업무 혁신의 길을 여는 데 중요한 역할을 할 것으로 기대된다.
